大数据工程师 岗位要求、成长路径与在线数据处理业务解析
一、大数据技术岗位的核心要求
大数据领域岗位多样,主要包括大数据开发工程师、大数据平台工程师、数据分析师、数据科学家等。虽然侧重点不同,但普遍要求以下核心能力:
- 扎实的技术栈基础:
- 编程语言:精通Java、Scala、Python(尤其是PySpark生态)至少一种,SQL是必备技能。
- 大数据生态框架:深入理解并掌握Hadoop(HDFS, YARN)、Spark(Core, SQL, Streaming)、Flink等核心计算与处理框架。对Hive、HBase、Kafka、ZooKeeper等组件的原理和应用有丰富经验。
- 数据存储与数仓:熟悉关系型数据库、NoSQL数据库(如Redis、MongoDB),并了解数据仓库建模理论(如维度建模)和OLAP技术(如ClickHouse、Doris)。
- 系统工程与平台能力:
- 能够进行集群规划、部署、监控、调优和故障排查,保障平台的稳定与高效。
- 熟悉Linux操作系统和Shell脚本,了解容器化技术(如Docker、Kubernetes)。
- 数据处理与开发能力:
- 具备从数据采集、清洗、存储、计算到可视化输出的全流程开发和架构设计能力。
- 能够编写高效、稳定、可维护的ETL/ELT任务代码,并具备良好的性能优化意识。
- 业务理解与软技能:
- 能够将模糊的业务需求转化为清晰的技术方案和数据产品。
- 具备良好的沟通能力、团队协作精神和强烈的责任心。
二、从入门到资深:大数据工程师的成长路径
成为一名资深的大数据工程师,通常需要经历以下阶段和持续努力:
- 夯实基础阶段(0-2年):
- 目标:掌握核心组件的使用和基础开发。
- 行动:深入学习一门编程语言和SQL,在本地或云环境搭建Hadoop/Spark集群,完成简单的数据处理项目。理解MapReduce、Spark RDD等基础编程模型。
- 能力深化阶段(2-5年):
- 目标:参与复杂项目,具备子系统或模块的设计能力。
- 行动:深入参与企业级数据平台建设,负责关键数据管道开发。深入研究框架源码(如Spark执行计划、Flink状态管理)、JVM及GC调优、资源调度优化。开始关注数据质量、数据治理和任务调度(如DolphinScheduler, Airflow)。
- 专家/架构阶段(5年以上):
- 目标:主导技术方向,进行系统架构设计和团队能力建设。
- 行动:
- 技术深度:能针对业务场景和技术瓶颈,进行框架选型、定制化改造甚至自研组件。
- 架构广度:设计高可用、高并发、可扩展的数据平台架构,平衡成本与性能。
- 业务影响力:推动数据驱动决策,通过数据架构赋能业务创新(如实时推荐、风控模型)。
- 方法论沉淀:建立团队开发规范、数据治理体系和技术演进路线图。
持续学习是贯穿始终的关键,需紧跟流批一体、湖仓一体、DataOps等前沿趋势。
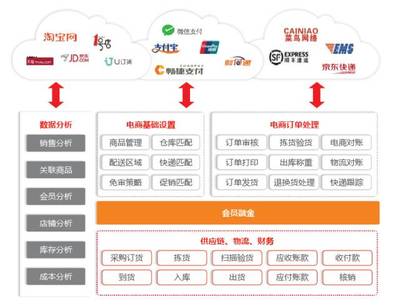
三、在线数据处理与交易处理业务(EDI & OLTP)中的大数据实践
在线数据处理(通常指联机分析处理OLAP)与在线交易处理(OLTP)是大数据技术赋能业务的两大核心场景。
- 场景特点与技术挑战:
- OLAP(在线数据分析):侧重于复杂查询和数据分析,数据量巨大,但更新频率较低。挑战在于查询速度和并发能力。常用技术包括预计算(物化视图)、列式存储(Parquet/ORC)、MPP架构数据库(ClickHouse)以及Spark SQL等。
- OLTP(在线交易处理):侧重于高并发、低延迟的短小事务处理(如订单支付、库存更新),要求极强的数据一致性和可用性。传统关系数据库是主力,但大数据技术如Kafka可用于解耦和流量削峰,Flink用于实时对账和风控。
- 大数据技术的融合应用:
- Lambda/Kappa架构:经典的大数据架构,兼顾实时(Speed Layer, 使用Flink/Spark Streaming)与批处理(Batch Layer, 使用Hive/Spark)需求,为业务提供从实时监控到历史深度分析的全方位数据服务。
- 实时数仓与数据湖:利用Flink CDC等技术实时捕获数据库变更日志,构建实时数据管道,将OLTP系统的数据实时同步到数据湖(如Iceberg/Hudi)或数仓中,支持秒级延迟的OLAP查询,实现“交易即分析”。
- 服务化与API化:将处理好的数据通过数据服务层(如GraphQL、Restful API)高效、安全地暴露给前端交易系统或其他应用,形成数据闭环。
而言,成为一名资深大数据工程师,不仅需要构建深厚的技术金字塔,更需深刻理解像在线数据处理与交易处理这样的核心业务场景,并能用大数据技术架起数据与业务价值之间的桥梁,驱动企业智能化升级。
如若转载,请注明出处:http://www.shuzicunzhi.com/product/61.html
更新时间:2026-02-25 13:05:39