OLTP on Hadoop: 在线数据处理与交易处理业务的技术实现
在当今数据驱动的时代,企业对于数据处理的需求日益多样化。传统上,Hadoop生态系统主要用于批处理和离线数据分析,但随着技术的发展,OLTP(在线事务处理)在Hadoop平台上的实现成为可能。本文将从技术架构的角度探讨OLTP on Hadoop的实践与应用。
一、OLTP on Hadoop的技术基础
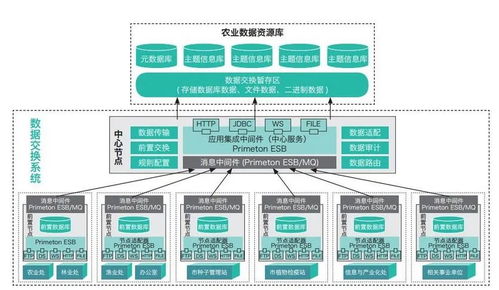
Hadoop生态系统最初设计用于处理大规模批量数据,但其架构的扩展性和容错性为OLTP应用提供了基础。通过HBase、Kudu等列式存储引擎,结合Apache Phoenix或Apache Trafodion等SQL引擎,可以实现低延迟的事务处理能力。这些组件共同构成了支持ACID事务的分布式数据库架构。
二、架构设计关键考量
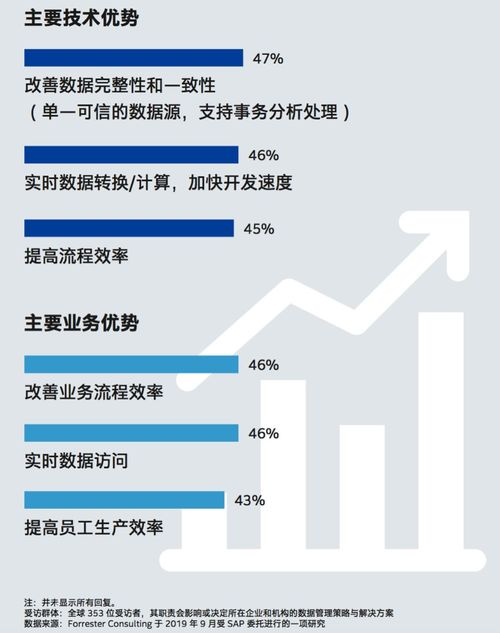
实现OLTP on Hadoop需要解决几个关键问题:首先是数据一致性,通过分布式事务协议确保跨节点的事务原子性;其次是低延迟访问,需要优化存储引擎和索引结构;最后是高可用性,通过多副本和故障自动转移机制保障系统持续可用。
三、典型应用场景
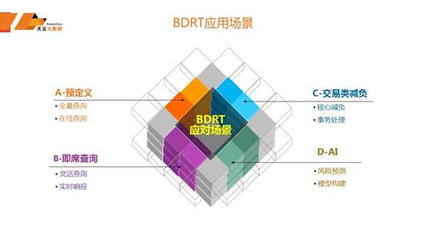
OLTP on Hadoop特别适合需要处理海量交易数据且具有分析需求的场景,如金融行业的实时风控、电商平台的交易处理、物联网设备数据采集等。这些场景既需要传统OLTP系统的事务保障,又需要大数据平台的扩展能力。
四、挑战与未来展望
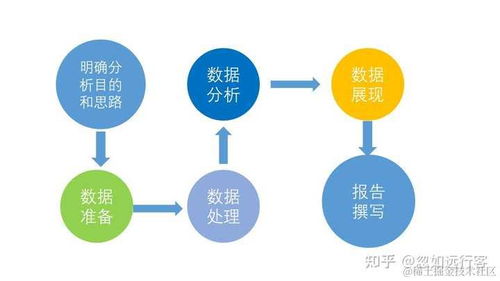
虽然OLTP on Hadoop技术日趋成熟,但仍面临一些挑战,包括复杂查询的优化、跨数据中心的同步、以及与传统系统的集成等。随着Apache Iceberg、Delta Lake等新一代数据湖技术的兴起,OLTP与OLAP的界限正在模糊,未来将出现更多融合事务处理与分析处理的一体化架构。
作为大数据技术架构师,我们需要在保证系统可靠性的前提下,持续探索新技术,为企业构建既能满足实时交易需求,又能支撑复杂分析的数据平台。OLTP on Hadoop的实现正是这种探索的重要方向,它将为企业的数字化转型提供更强大的数据基础设施支持。
如若转载,请注明出处:http://www.shuzicunzhi.com/product/30.html
更新时间:2026-06-04 08:13:12